Investigating Duplicate HTML Requests on a Page Load
Why it occurs, and what is the impact on web performance?
Overview
Ever see a web page load an embedded object that is really the same HTML as the main document? I’ve seen this show up on a handful of websites recently - including a few large ecommerce sites, a news site, a financial services site and a utility company’s website. Every time I’ve run into this, I’ve said I need to write a blog post about it. So, here’s that post!
Two of the most recent ones I’ve seen made the same mistake. Can you spot the error?

The body was styled with the CSS background property, which is shorthand for background-color, background-url, and others (this is explained better here). In this example, the developer probably wanted to use background: none to give a blank background color, but used an empty URL instead. The url() function attempts to load a background image, and it takes a string as an argument. Since an empty string is a valid string this doesn’t trigger an error in the console. It simply results in a relative request to the base URL.
I created a simple test page to demonstrate this. In the WebPageTest waterfall below you can clearly see the extra page request.

In Chrome DevTools, you would see the duplicate request show up with an initiator of the main document. In the console there is no indication or an error. This may not be a technical error, but it certainly is unintentional and comes with a performance penalty.

In this article we are going to explore why this is a performance issue, how duplicate requests for HTML can be inadvertently triggered, and how you can avoid them.
What is the Performance Impact?
For many sites, HTML pages are dynamically generated - which means that there is a backend cost associated with delivering the content. We often measure this by using the Time to First Byte metric, which tells us the time from when a request was made until the browser starts to receive a response. Often these pages are not cacheable either - so each request gets handled dynamically.
The overall capacity of the application backend is usually driven by the its ability to process the workload volume it receives. And if you are accidentally sending twice the number of requests for a dynamically generated HTML page, your infrastructure could be working twice as hard for nothing.
For example:
- If the backend is struggling to keep up with the load, then all pages will be affected. This has the potential to degrade time-to-first-byte for all pages.
- There are costs involved with scaling out capacity at the origin. Unnecessary HTML requests can skew capacity planning in this case.
Increased page weight is an additional reason. Many of the examples below were used to generate placeholders or empty content. In these cases, the additional HTML could be unnecessarily increasing page weight.
What Causes This?
Here are a few reasons I’ve seen for duplicate HTML requests
<body style="background: url('')">
This is the example I started off this post with. When you style an element with a background URL using url(), any string is considered a value argument. Since url(‘ ‘) is passed a valid string, it gets translated to a relative URL. This triggers a duplicate request in Chrome as well as Firefox. Safari ignores the empty url string
This also applies to other elements that can be styled with a background URL. For example, <div style="background: url()">
And it also happens with url(), url('') and url(' ')!
Element src’s with ? or # For some elements, a src attribute of either “?” or “#” would get interpreted that as a blank relative URL. For example <img src=”#” /> looks like an empty placeholder image, but it will cause the base HTML to get fetched again.
The same applies for <script>, <iframe>, and <video> - although browsers vary a bit. For example:
src=” “returns a duplicate request for Firefox, but not the other browsers.<script src=”#” />also affects only Firefox<script src=”?” />affects only Chrome browsers- Chrome does not send duplicate requests for relative video src attributes, but Firefox and Safari do.
The table below lists the full summary of the tests I ran across Chrome, Safari and Firefox to see how they handle these errors. A warning icon indicates that they result in multiple HTML requests -
| Chrome | Safari. | Firefox | |
|---|---|---|---|
<img src="#" /> | |||
<img src=" " /> | |||
<img src="?" /> | |||
<script src="#" /> | |||
<script src=" " /> | |||
<script src="?" /> | |||
<iframe src="#" /> | |||
<iframe src=" " /> | |||
<iframe src="?" /> | |||
<video src="#" /> | |||
<video src=" " /> | |||
<video src="?" /> | |||
<body style="background: url()"> | |||
<body style="background: url('')"> | |||
<body style="background: url(' ')"> | |||
<div style="background: url()"> | |||
<div style="background: url('')"> | |||
<div style="background: url(' ')"> |
* iFrames with src=”?” and “#” resulted in 3-4 HTML requests for the same page.
Service worker Cache
Creating a separate cache layer via a service worker is a great way to preload your browser cache for resources that it will need later. However, what happens when you include an HTML page as one of those resources to fetch?
Here’s an example of a site doing exactly that. Even worse, the HTML was not cacheable…
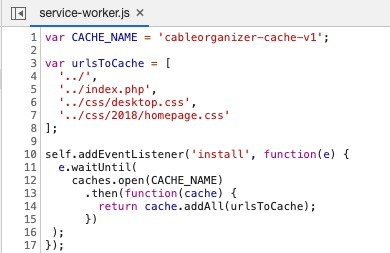
If you are going to use a service worker to cache a resource, make sure that resource is cacheable!
display:none
While this example is not specifically about HTML, it occurs enough that it’s worth mentioning. As @dougsillars says “display:none does not mean download:none”.
Your periodic reminder that using "display:none" in your CSS does not also mean "download:none" pic.twitter.com/eZZNnrQ3OS— Doug Sillars 🇬🇧 (@dougsillars) May 17, 2020
In this example, the developer referenced video content that used a media query to hide the video for certain screen sizes. The end result was downloading both the desktop and mobile videos, while hiding one of them. That’s a lot of wasted bytes!
Why do I bring this up in an article about duplicate HTML requests? I’ve seen some cases of this technique used alongside <img src="#" /> - resulting in duplicate HTML!
How to Detect?
There aren’t any tools or audits I know of that look for this, as it does tend to be a bit of a niche error.
Probably the easiest way to spot this is by looking at the CPU processing overlay in WebPageTest. If you see JS execution for a request before the request is loaded, then it was likely a duplicate.

In DevTools, you can also filter by your domain name using domain:www.example.com. Filtering and sorting by name, makes these easier to spot. If you see the same URL with a type of both document and text/html, then you are loading a duplicate HTML page.
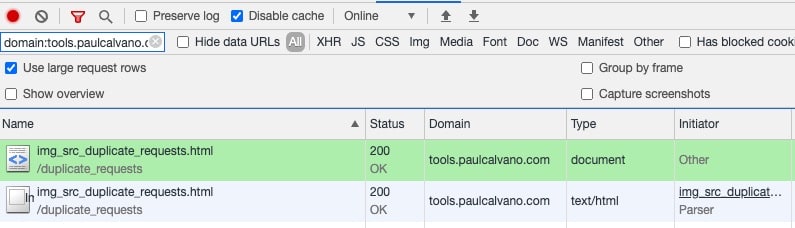
Clicking on the initiator can help find what caused the duplicate HTML to load.
Conclusion
If you are analyzing a page and see what looks like a duplicate request for the base HTML page, don’t ignore it! This could be a serious performance and capacity issue. Instead use DevTools to attempt to locate what initiated that request. You may find that you have accidentally included a placeholder or set an incorrect CSS property or element src attribute.
